
Just like a coin has two sides, Material Sensing is made up of two equally important technologies – spectroscopy and chemometrics. Spectroscopy is used to measure materials; it is the technology that enables our handheld device to take measurements. Once these measurements have been conducted, the data is transferred to the corresponding software. This is where chemometrics comes into the picture. You can imagine it as a complex algorithm that reads and interprets the input data and provides you with easy-to-understand results.
It is important to know that each chemometric model can only answer one specific question. For example, to quantify the amount of cotton in a cotton-polyester blend, you require a chemometric model. To enable you to quantify the cotton in a cotton-silk blend, you require another chemometric model. Even though these applications are very similar, they require different chemometric models.
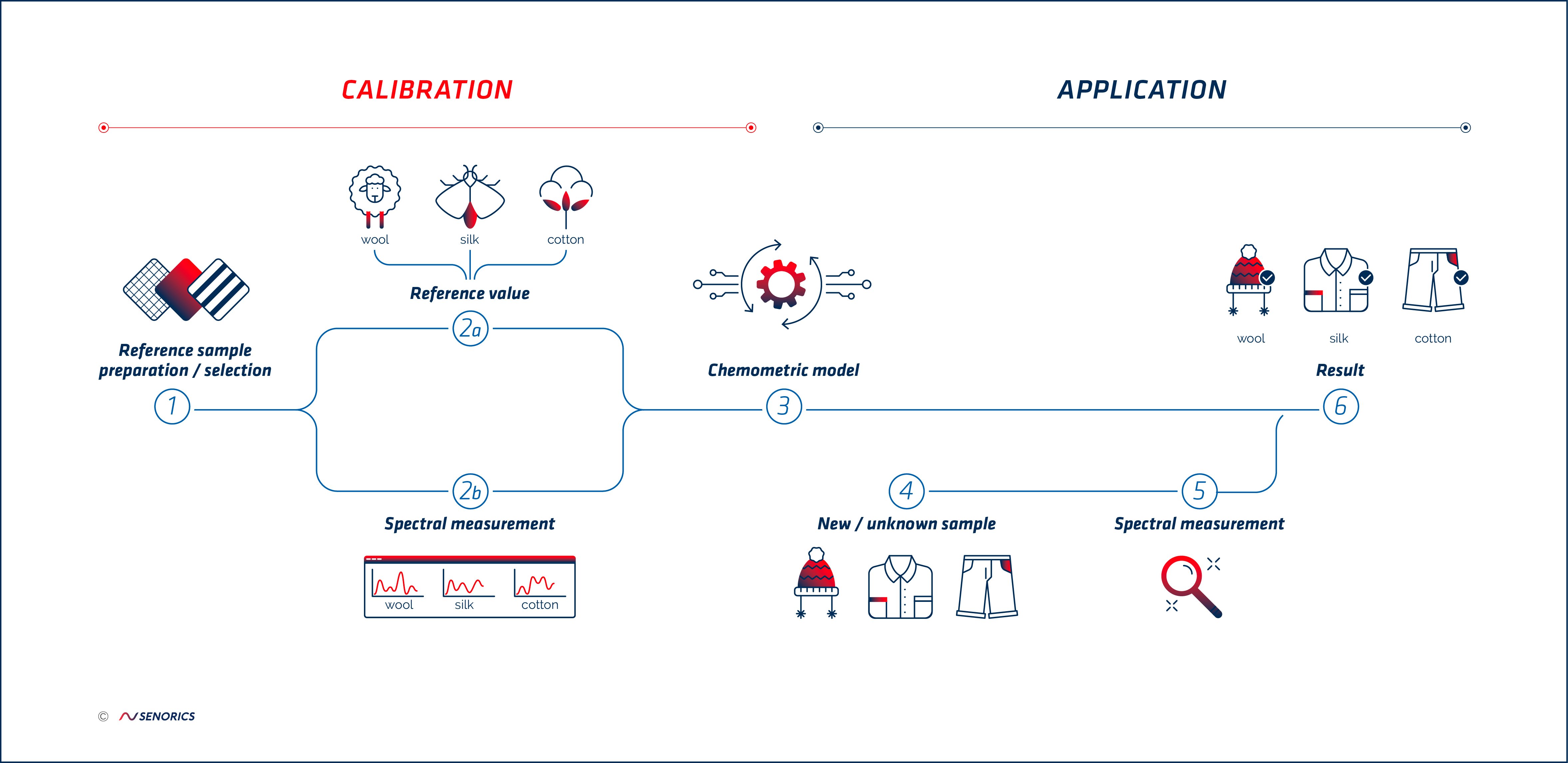
So, to develop an application that can answer a specific query, we first have to build a chemometric model. This is done in two phases: calibration and application. During calibration, the models are trained and during application, the previous training allows the model to output relevant results.
In this article, we would like to give you a better understanding of the creation of chemometric models.
Calibration
Choosing the right samples
First, we need to select relevant samples (1). For example, if your goal is to identify whether your scarf is made of cotton or polyester, you will require a sufficient number of different samples that are made of …
- pure cotton
- pure polyester
- blends of cotton and polyester with different ratios
Conducting measurements
The next step is to take spectroscopic measurements of each sample (2b). Through that process, we obtain spectral data. In order to build a robust model and ensure reliable results, multiple measurements need to be conducted in a precise way. For that, the SenoCorder is placed in various different spots on each sample and several measurements are recorded.
If you would like to learn more about the measurement process, you can find information in this article on the 4 steps of conducting measurements for Material Sensing.
Receiving reference values
In addition to undertaking spectral measurements, we also need to gather reference values for the selected cotton and polyester samples (2a). This is done to make sure that they are what they appear to be, e.g., that the cotton samples really are made from cotton, and not from polyester.
We can obtain these reference values from external labs. It is important that the reference values are obtained through other analysis methods, e.g., wet chemical analysis. The reference values can not be recorded with the SenoCorder.
Combining the data
We then combine the reference values and the spectral data to train the chemometric model (3) and prepare it for the application phase. This involves the use of multiple algorithms specially developed by our data science team.
Application
The chemometric model we have calibrated will then be used to identify cotton and polyester in textiles. This means you can measure an unknown sample (4-5) and receive information about its properties (6). If you measure your scarf, you will immediately know whether it is made from cotton, polyester, or a mixture of both.
To sum things up, this is what we’ve learned today:
- A chemometric model is customized depending on its application, meaning there is no general chemometric model but rather a different model for each situation.
- You can only interpret unknown samples correctly if they are composed of the same materials that you used during the calibration. For example, if you use cotton and polyester reference samples, the model can only identify other samples made of cotton or polyester, it will not be able to identify silk.
Chemometric models are complex systems and to build them requires a considerable amount of experience and knowledge in the field. This is why we build the models for our customers rather than leaving it up to them. If you are looking for a certain application and would like us to help you realize it, contact us at inquiry@senorics.com.


